모델 학습에 대해
모델 학습을 시도하면서 마주한 문제들을 해결하면서 배운 것들
🤔Loss가 계속 fluctuate 한다
모델을 학습할 때 확인해야할 요소들
- optimizer
- learning rate sechduling
- model capacity (=size)
- data
여기서 (3) model capacity랑 (4) data가 overfitting인지 underfitting인지를 결정한다. 만약 모델이 데이터보다 더 크다면 underfitting 데이터보다 모델이 더 크다면 underfitting인 것이다.
Optimizer and Learning Rate
- Adam optimizer의 경우, 저절로 lr를 바꾼다는 것을 기억해야한다.
- Stimulated Annealing
- 담금질 기법. 즉, 온도가 올라갔다가 내려가면서 형태가 보다 쉽게 변화할 수 있/없음을 의미한다.
- 온도가 올라간다 (= lr이 높다) : 더 쉽게 변화한다는 의미. lr이 더 높으니까, 더 큰 보폭으로 움직이기에 변화가 더 크다.
- 만약 lr가 큰 값에서 작은 값으로 변화할 때 loss에서 큰 감소가 있다면, 큰 보폭으로 해당 convex 사이에서 지그재그로 학습되다가, 보폭이 줄어드는 순간 gobal minimum에 가까워졌다고 생각할 수 있는 것이다.
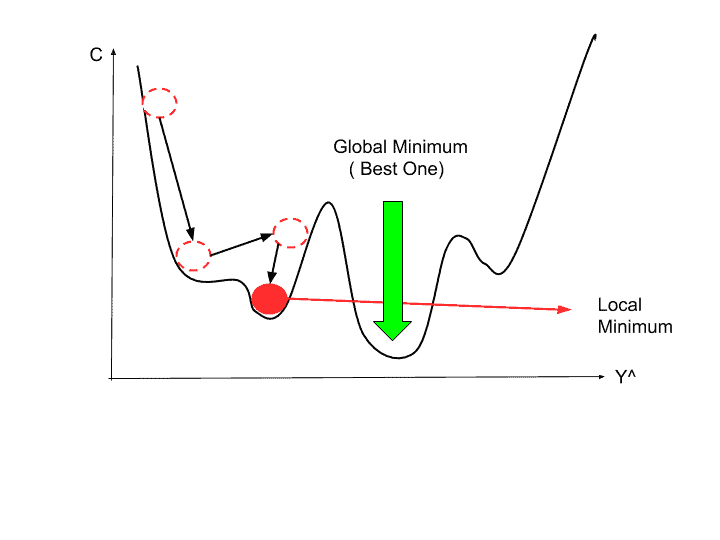
Model Capacity
- 만약 모델의 loss가 충분히 낮지 않으면 model capacity가 너무 작아서, 즉, 너무 작은 모델로 학습을 시키고 있어서 그럴 수 있다 (또는 데이터의 노이즈가 너무 많아서 그런 것일 수도 있다).
- 더 큰 모델로 학습시켜보는 것도 좋은 방법이 될 수 있다.
내가 확인한 문제의 경우 더 복잡한 모델을 사용했을 때 fluctuation이 줄었고 loss도 더 낮게 수렴했다.
Stochastic GD vs. “Regular” Gradient Descent
- Stochastic의 의미 : 확률론적
- Stochastic의 경우 배치로 나눠서 일부의 데이터로 다음 결정을 내린다면, 일반적인 gradient descent의 경우 모든 데이터를 기반으로 다음 결정을 내리는 것이다.
- 그렇기 때문에 많은 데이터로 학습을 시킬경우 SGD를 사용하는 것이다.
This iterative process continues with randomly selected training examples until the algorithm reaches a predetermined stopping point. This method is preferred when working with large datasets because it takes less time to process a single example than it does to process the entire dataset. (source)
😎직접 시도
- 사용한 모델 : PaddlePaddle의 PaddleYOLOE+ (batch size : 16)
- vibrant-wave-12 (주황색) : PP-YOLOE+_s
- usual-violet-8 (보라색) : PP-YOLOE+_m
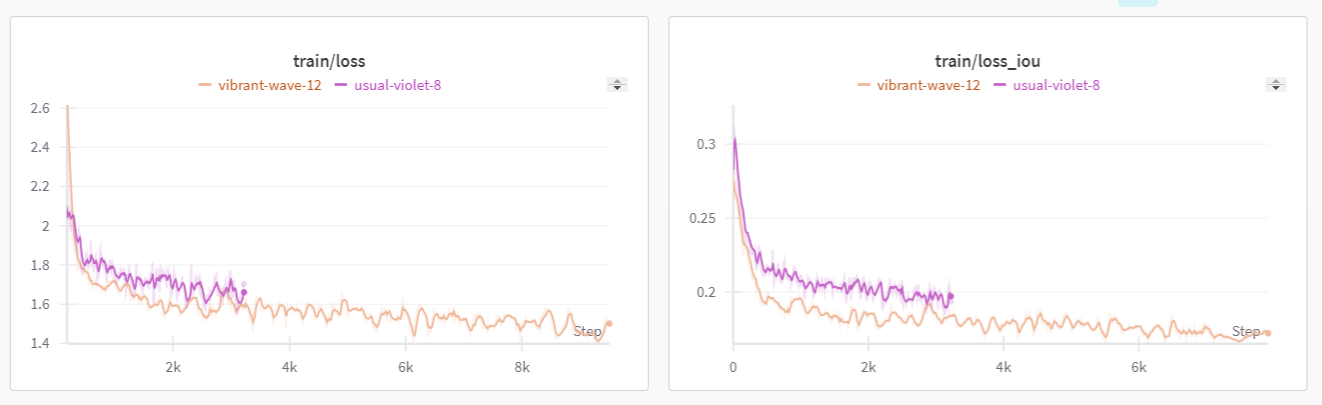
모델의 사이즈를 키워서 다시 돌려봤을 때(주황색) 전보다는(보라색) 확실히 더 안정적인 커브를 확인할 수 있었다.
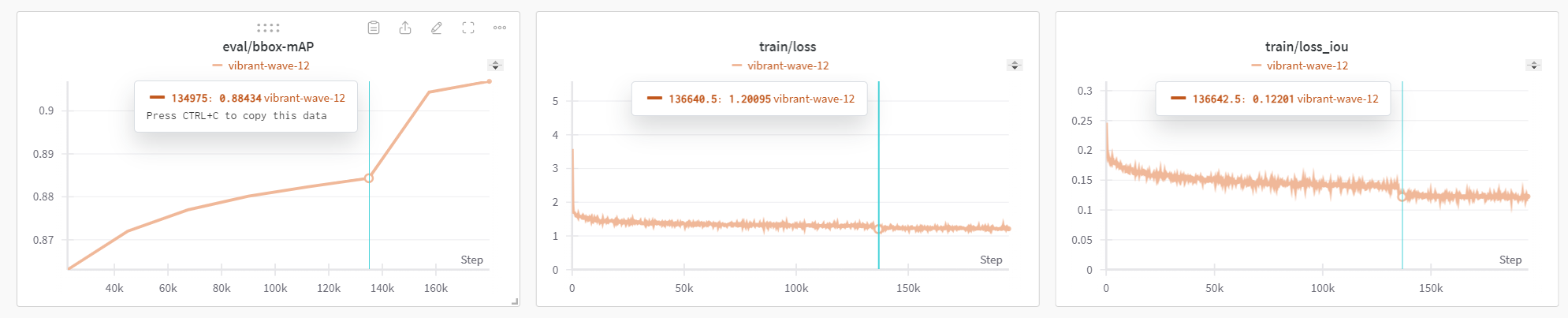
- 또 위에서 언급한 “보폭이 확 줄어드는 순간 loss의 급격한 변화”를 직접 확인할 수 있었다.
- 지금 gpu의 메모리가 부족해서 모델의 크기를 더 키우고 배치 사이즈를 늘리지 못하는 상황이 아쉬운 부분
This post is licensed under CC BY 4.0 by the author.